MySQL 优化
6年前
978
0
当 MySQL 单表记录数过大时,增删改查性能都会急剧下降,本文会提供一些优化参考,大家可以参考以下步骤来优化
表单优化
除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑、部署、运维的各种复杂度。
一般以整型值为主的表在千万级以下,字符串为主的表在五百万以下是没有太大问题的。
而事实上很多时候 MySQL 单表的性能依然有不少优化空间,甚至能正常支撑千万级以上的数据量。
字段
- 尽量使用 TINYINT、SMALLINT、MEDIUM_INT 作为整数类型而非 INT,如果非负则加上 UNSIGNED。
- VARCHAR 的长度只分配真正需要的空间。
- 使用枚举或整数代替字符串类型。
- 尽量使用 TIMESTAMP 而非 DATETIME
- 单表不要有太多字段,建议在 20 以内
- 避免使用 NULL 字段,很难查询优化且占用额外索引空间
- 用整型来存 IP
- order by null 会提高查询速度
- 使用同类型进行比较,比如用 ‘123’ 和 ‘123’ 比,123 和 123 比。
- 尽可能把所有列定义为not null
- 索引NULL列需要额外的空间来保存,所以要占用更多的空间
- 进行比较和计算时要对NULL值做特别的处理
- 使用 TIMESTAMP 或者 DATETIME 类型存储时间
- TIMESTAMP 1970-01-01 00:00:01 ~ 2038-01-19 03:14:07
- TIMESTAMP 占用4字节和 INT 相同,但比 INT 可读性高
- 超出 TIMESTAMP 取值范围的使用 DATETIME 类型
索引
- 索引并不是越多越好,要根据查询有针对性的创建,考虑在 WHERE 和 ORDER BY 命令上涉及的列建立索引,可根据 EXPLAIN 来查看是否用了索引还是全表扫描。
- 可通过开启慢查询日志来找出较慢的 SQL。
- 应尽量避免在 WHERE 子句中对字段进行 NULL 值判断,否则将导致引擎放弃使用索引而进行全表扫描。
- 值分布很稀少的字段不适合建索引,例如“性别”这种只有两三个值的字段
- 字符字段最好不要做主键。
- 尽量不用 UNIQUE和外键, 由程序保证约束。
- 使用多列索引时注意顺序和查询条件保持一致,同时删除不必要的单列索引。
- 限时表索引的数量,避免建立重复和冗余索引
- 注意合理选择复合索引键值的顺序
- 区分度最高的列放在联合索引最左侧
- 尽量把字段长度小的列放在联合索引最左侧
- 使用最频繁的列放在联合索引最左侧
索引的优化
可以使用EXPLAIN分析SQL查询
具体内容:可阅读 MySQL Explain详解
sql语句
- 不用SELECT *。
- SQL 语句尽可能简单:一条 SQL只能在一个 CPU 运算;大语句拆小语句,减少锁时间;一条大 SQL 可以堵死整个库。
- 避免 %xxx 式查询。
- 联表查询时,少用 JOIN 可以考虑用where in。
- OR 改写成 IN:OR 的效率是 n 级别,IN 的效率是 log(n) 级别,IN 的个数建议控制在 200 以内。
- 尽量避免在 WHERE 子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描。
- 列表数据不要拿全表,要使用 LIMIT 来分页,每页数量也不要太大。
- 分页时如果数据量大
- 使用where id>10000 limit 20。
- 用子查询: select * from table where status=1 limit 1000000,20 改为 select a.* from (select id from table where status=1 limit 1000000,20) as b, table as a where a.id=b.id 先做一个子查询查出 id(只会在索引里面扫描),然后关联查询,这样扫描的行数是限定的。而不会扫描表前面所有的行
- 避免使用子查询,可以把子查询优化成join操作
- 子查询的结果集无法使用索引
- 子查询会产生临时表操作,如果子查询数据量大则严重影响效率
- 不做列运算:SELECT id WHERE age + 1 = 10,任何对列的操作都将导致表扫描,它包括数据库教程函数、计算表达式等等,查询时要尽可能将操作移至等号右边。
- 对于连续数值,使用 BETWEEN 不用 IN:SELECT id FROM t WHERE num BETWEEN 1 AND 5。
- 建议使用预编译语句进行数据库操作
- 只传参数,比传递SQL语句效率更高
- 相同语句可以一次解析,多次使用,提高处理效率
- 使用 in 替换 or
- in 的值不要超过500个
- in 操作可以有效的利用索引
- where从句中禁止对列进行函数转换和计算
- 对进行函数转换或计算会导致无法使用索引
- 例如 :where date(createtime)= ‘20181010’
- 拆分复杂的大SQL为多个小SQL
- 因为MySQL一个SQL只能使用一个CPU进行计算
- SQL拆分后可以通过并行执行来提高处理效率
引擎
目前广泛使用的是 MyISAM 和 InnoDB 两种引擎:
MyISAM
- MyISAM 引擎是 MySQL 5.1 及之前版本的默认引擎
- 不支持行锁,读取时对需要读到的所有表加锁,写入时则对表加排它锁。
- 不支持事务。
- 不支持外键。
- 不支持崩溃后的安全恢复。
- 在表有读取查询的同时,支持往表中插入新纪录。
- 支持 BLOB 和 TEXT 的前 500 个字符索引,支持全文索引。
- 支持延迟更新索引,极大提升写入性能。
- 对于不会进行修改的表,支持压缩表,极大减少磁盘空间占用。
InnoDB
- InnoDB 在 MySQL 5.5 后成为默认索引
- 支持行锁,采用 MVCC 来支持高并发。
- 支持事务。
- 支持外键。
- 支持崩溃后的安全恢复。
总体来讲,MyISAM 适合 SELECT 密集型的表,而 InnoDB 适合 INSERT 和 UPDATE 密集型的表。
表分区
MySQL 在 5.1 版引入的分区是一种简单的水平拆分,用户需要在建表的时候加上分区参数,对应用是透明的无需修改代码。
对用户来说,分区表是一个独立的逻辑表,但是底层由多个物理子表组成,实现分区的代码实际上是通过对一组底层表的对象封装,但对 SQL 层来说是一个完全封装底层的黑盒子。
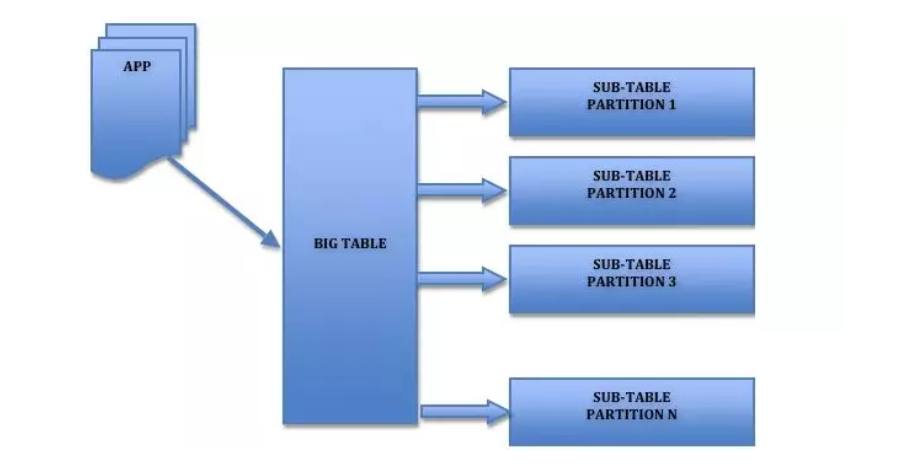
MySQL 实现分区的方式也意味着索引也是按照分区的子表定义,没有全局索引。
用户的 SQL 语句是需要针对分区表做优化,SQL 条件中要带上分区条件的列,从而使查询定位到少量的分区上,否则就会扫描全部分区。
可以通过 EXPLAIN PARTITIONS 来查看某条 SQL 语句会落在那些分区上,从而进行 SQL 优化。
<font color=#1ab394>如下图 5 条记录落在两个分区上:</font>
mysql> explain partitions select count(1) from user_partition where id in (1,2,3,4,5);
+----+-------------+----------------+------------+-------+---------------+---------+---------+------+------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+----------------+------------+-------+---------------+---------+---------+------+------+--------------------------+
| 1 | SIMPLE | user_partition | p1,p4 | range | PRIMARY | PRIMARY | 8 | NULL | 5 | Using where; Using index |
+----+-------------+----------------+------------+-------+---------------+---------+---------+------+------+--------------------------+
1 row in set (0.00 sec)
<font color=#1ab394>分区的好处是:</font>
- 可以让单表存储更多的数据。
- 分区表的数据更容易维护,可以通清除整个分区批量删除大量数据,也可以增加新的分区来支持新插入的数据。另外,还可以对一个独立分区进行优化、检查、修复等操作。
- 部分查询能够从查询条件确定只落在少数分区上,速度会很快。
- 分区表的数据还可以分布在不同的物理设备上,从而高效利用多个硬件设备。
- 可以使用分区表来避免某些特殊瓶颈,例如 InnoDB 单个索引的互斥访问、 ext3 文件系统的 inode 锁竞争。
- 可以备份和恢复单个分区。
<font color=#1ab394>分区的限制和缺点:</font>
- 一个表最多只能有 1024 个分区。
- 如果分区字段中有主键或者唯一索引的列,那么所有主键列和唯一索引列都必须包含进来。
- 分区表无法使用外键约束。
- NULL 值会使分区过滤无效。
- 所有分区必须使用相同的存储引擎。
<font color=#1ab394>分区的类型:</font>
- RANGE 分区:基于属于一个给定连续区间的列值,把多行分配给分区。
- LIST 分区:类似于按 RANGE 分区,区别在于 LIST 分区是基于列值匹配一个离散值集合中的某个值来进行选择。
- HASH 分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含 MySQL 中有效的、产生非负整数值的任何表达式。
- KEY 分区:类似于按 HASH 分区,区别在于 KEY 分区只支持计算一列或多列,且 MySQL 服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
分区适合的场景有:最适合的场景数据的时间序列性比较强,则可以按时间来分区。
<font color=#1ab394>如下所示:</font>
CREATE TABLE members (
firstname VARCHAR(25) NOT NULL,
lastname VARCHAR(25) NOT NULL,
username VARCHAR(16) NOT NULL,
email VARCHAR(35),
joined DATE NOT NULL
)PARTITION BY RANGE( YEAR(joined) ) (
PARTITION p0 VALUES LESS THAN (1960),
PARTITION p1 VALUES LESS THAN (1970),
PARTITION p2 VALUES LESS THAN (1980),
PARTITION p3 VALUES LESS THAN (1990),
PARTITION p4 VALUES LESS THAN MAXVALUE
);
查询时加上时间范围条件的效率会非常高,同时对于不需要的历史数据能很容易的批量删除。
如果数据有明显的热点,而且除了这部分数据,其他数据很少被访问到,那么可以将热点数据单独放在一个分区,让这个分区的数据能够有机会都缓存在内存中,查询时只访问一个很小的分区表,能够有效使用索引和缓存。
另外 MySQL 有一种早期的简单的分区实现 - 合并表(merge table),限制较多且缺乏优化,不建议使用,应该用新的分区机制来替代。


